Последние пару недель я играю в симулятор капитализма “Simcracy”. Давайте все регистрируйтесь и становитесь моими рефералами, вам от этого хуже не будет, а мне дополнительно золото придёт.
Ну ладно, если вы против рефералов – вот чистая регистрация.
Чтобы вам далеко не ходить, тут же расскажу вкратце, как устроена игра, и как в неё играть.
Как устроена игра
В Симкраци вы строите рудники, добываете ресурсы и продаёте их – в этом суть игры. Из одних ресурсов можно производить другие, более сложные, например, из песка делать стекло – для этого нужны специальные фабрики. И, наконец, из ресурсов можно делать различные предметы, которые нужны для игровых действий – еду, медикаменты, учебники и оружие.
Цели у игры нет, но можно пытаться разбогатеть, получить влияние среди игроков, захватить большую территорию или установить какой-то общественный строй.
Итак, вы начали играть.
Выбор участка
Земля на планете разделена на зоны. Каждая зона принадлежит какому-то государству либо нейтральна, и вы можете выбрать, в каком месте купить участок земли. Лучше всего выбирать нейтральную зону, поскольку торговать вы сможете только на рынке своей страны, а нейтральный рынок сейчас самый развитый и не облагается налогами.
В каждой зоне свои бонусы на разные типы ресурсов: есть такие, где легко добывать нефть, есть – где навалом песка. Выбирая себе дом, подумайте, на каком ресурсе станете зарабатывать. Более простые ресурсы (дерево, глина) сразу принесут доход, но рынок насыщен ими. Более сложные – например, нефть – помогут извлечь выгоду, когда вы немного разовьёте своё производство.
В каждой зоне свой мэр – или нет мэра. Мэры избираются голосованием игроков этой зоны с уровнем выше 18, и единственное, что могут делать – брать с вас налоги за работу. Так что выгоднее найти заброшеную зону без мэра, или такую зону, где уверенно лидирует мэр, не ставящий налогов. Мэров сейчас немного.
Если вы играете не на нейтрале, налоги за торговлю на рынке может брать президент – это ещё одна причина обосноваться на нейтрале, по крайней мере, на первых порах.
Чтобы добраться до нужной зоны, до неё нужно пропутешествовать. Это лучше делать не пешком, а на велосипеде – и один велосипед вам как раз дарят при регистрации. Переключение в режим карты мира доступно из меню игры, а чтобы переключиться на просмотр зоны, на неё нужно нажать.
Кроме государственной принадлежности зоны нет никакой разницы, где вы поселитесь. Перевозить ресурсы не надо – торговля возможна на любом расстоянии. Вы не получите никаких преимуществ, поселившись рядом с другими людьми, так что выбирайте зону исключительно исходя из её бонусов.
Выработка ресурсов
Теперь у вас есть участок. Чтобы зарабатывать деньги, нужно добывать ресурсы, а для этого надо построить рудник. На постройку простого рудника вам как раз хватит начальных ресурсов – обычно требуется только дерево.
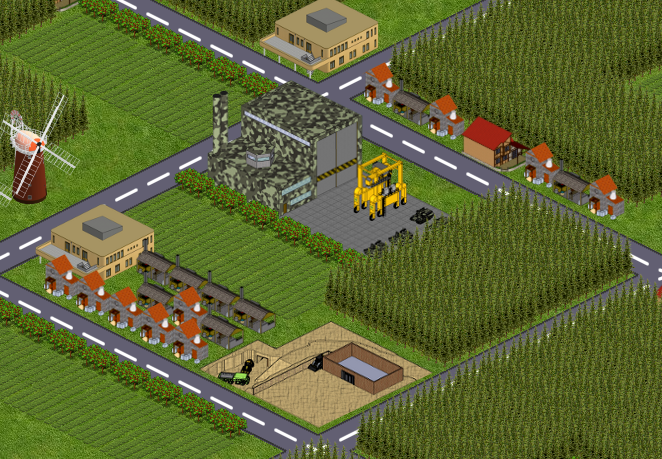
На руднике нужно работать. При этом вы расходуете энергию – а восстанавливается она неторопливо. Таким образом, в день вы можете совершить лишь ограниченное количество работы, и лучше тратить её с максимальной пользой. Энергия – самый ценный и единственный невосполнимый ресурс в игре.
Кроме того, для работы нужно быть сытым на 120 очков, а для этого потреблять еду. Не бойтесь – на первых порах вы едой обеспечены очень хорошо. Однако не ешьте просто так: с голоду вы не умрёте. Расходуйте еду только перед тем, как начать работать.
Ваш рудник приносит не слишком много ресурсов в день, и когда дневная норма выработана, дальше вы на нём работать не можете – остаётся только ждать. Чтобы увеличить дневную норму и сделать работу на руднике более эффективной (тратящей меньше энергии), рудники можно апгрейдить. Для этого тоже нужны ресурсы.
Рудник по добыче леса начального уровня требует около 0.75 энергии и столько же сытости для совершения единицы работы и добычи единицы леса. Этот же рудник, апгрейженный до десятого уровня, требует около 0.35 энергии и совсем незначительное количество сытости. Так что апгрейдить рудники – это выгодное вложение денег. Вы сможете добывать на них больше и эффективнее.
Поскольку энергия восстанавливается быстрее, чем дневная норма на руднике, часто имеет смысл поставить несколько рудников, чтобы ваша энергия не простаивала.
Если зона имеет бонус к ресурсу, то рудники по добыче этого ресурса будут сразу требовать меньше энергии и сытости за единицу работы. Однако количество добытого ресурса за единицу работы всегда будет неизменным.
Рынок
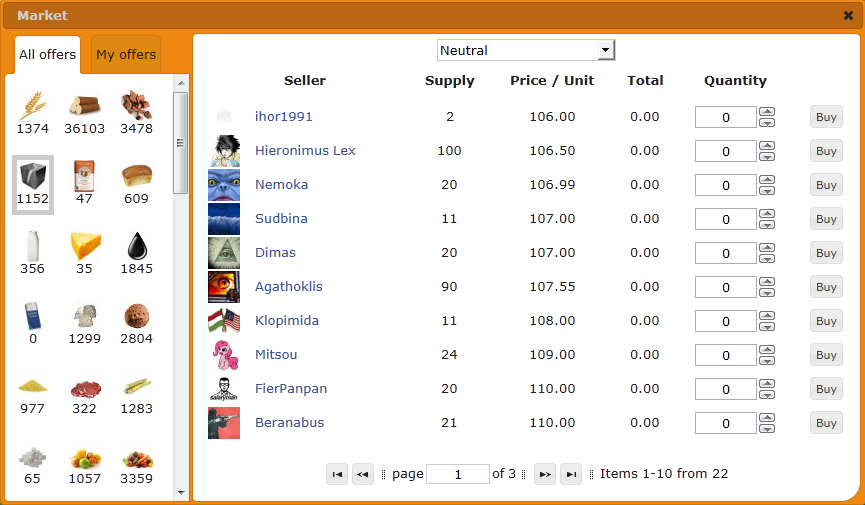 Добытые ресурсы можно использовать самому, а можно продать. Для этого существует рынок, доступный из меню игры. Цены на рынке пока не устоялись и постоянно падают, так что если вы хотите, чтобы ваше предложение нашло спрос, нужно назначать цену, близкую к минимальным предложениям конкурентов – или даже меньше. Вы убедитесь, что вашу небольшую цену всё равно скоро кто-нибудь перебьёт.
Добытые ресурсы можно использовать самому, а можно продать. Для этого существует рынок, доступный из меню игры. Цены на рынке пока не устоялись и постоянно падают, так что если вы хотите, чтобы ваше предложение нашло спрос, нужно назначать цену, близкую к минимальным предложениям конкурентов – или даже меньше. Вы убедитесь, что вашу небольшую цену всё равно скоро кто-нибудь перебьёт.
Разумеется, ресурсы на рынке можно и покупать. Если вы производите лес, а для апгрейда лесопилки вам нужен камень – гораздо выгодней купить его по дешёвой цене, чем строить каменоломню, апгрейдить её и работать на ней, тратя бесценную энергию.
Квесты
Из игрового меню доступен пункт “Квесты” – это задания для новичков, выполнение которых принесёт вам бесплатно некоторое количество ресурсов. Прочитайте эти задания и выполните их – большинство из них простые.
Сложные ресурсы
Некоторые ресурсы можно перерабатывать в другие. Для этого нужны фабрики, которые тоже можно апгрейдить, как и рудники.

Если простые ресурсы обычно добываются по единице за единицу работы, то для производства сложных товаров уже часто требуется десять или двадцать, а то и несколько сотен единиц работы. Также на фабриках и рудниках часто можно переключать режим производства: одна и та же фабрика способна производить разные товары. Например, кузня может производить:
– 1 железо за 10 работы (потребив 10 дерева и 2 руды)
– 1 нож за 220 работы (потребив 60 дерева и 10 железа)
Не обязательно вкладывать всю работу сразу: здание запоминает, какая часть ножа уже сделана.
Бонусов для вторичных ресурсов и товаров не существует. Их производство одинаково эффективно в любой зоне.
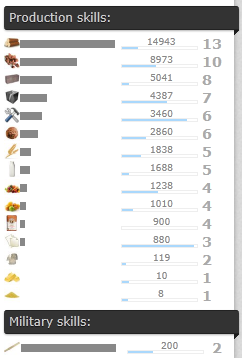
Навыки
Чем больше вы добываете лес или вырабатываете песок из стекла, тем лучше у вас это получается. На странице настроек персонажа можно посмотреть, какие навыки у вас насколько развиты. При высоком навыке на единицу одной и той же работы у вас уйдёт меньше энергии и сытости (выработка с единицы работы будет той же).
Поэтому выгоднее не метаться между разными производствами, а вложить все силы в добычу или изготовление чего-то одного. Со временем вам это будет даваться куда лучше, чем другим начинающим.
Навыки можно искусственно повышать в школах, но за это придётся платить хозяевам школ. Список школ доступен из меню игры. Отношение к ним встречается разное: на мой взгляд, они бесполезны, и гораздо выгодней развивать навык, работая на руднике – но у успешных игроков я встречал и обратное мнение.
Прокачиваясь в школах, вы ничего не производите, быстро повышаете выбранный навык, но совсем не повышаете общий уровень персонажа. Работая на руднике, вы повышаете и навык, и уровень персонажа с одинаковой нормальной скоростью.
От уровня персонажа зависит несколько привелегий: возможность покупать второй участок земли (кажется, 12-й уровень), баллотироваться в мэры и голосовать за мэра (18-й уровень) и участвовать в выборах президента (21-й уровень).
Найм
Вместо того, чтобы работать на руднике самому, можно нанять других. Для этого достаточно установить цену за единицу работы в настройках рудника, и ваше предложение появится в списке работы, доступном из игрового меню.
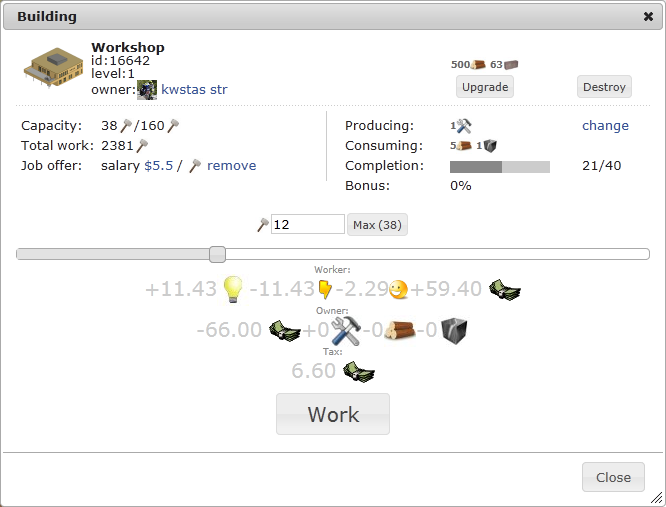
Обратите внимание, что цена назначается за единицу работы, а не потраченной энергии и не произведённого товара. Затраты энергии на единицу работы зависят от уровня рудника, от бонусов зоны и от навыка работника. Для нанимателя неважно, прокачан рудник или нет, и какой навык у работника. Сколько бы энергии не затратил работник на единицу работы, он получит одну и ту же плату. А поскольку за единицу работы рудник всегда даст одно и то же количество ресурсов, можно считать, что назначая зарплату, вы просто приобретаете ресурс по соответствующей цене.
Наоборот, с точки зрения работника, имеет смысл внимательно выбирать, на какой рудник наниматься. Смотреть следует не только на зарплату, но и на то, сколько энергии придётся потратить на этом конкретном руднике за одну единицу работы.
Существование навыков и найма открывает стратегию развития “профессионал”: не строить рудников и фабрик, а вместо этого работать на других, прокачивая свой навык какого-то одного производства.
Однако сейчас биржа труда в игре устроена таким неудобным образом, что пользоваться ей практически невозможно, и рынок труда не развит. Не рассчитывайте нанять людей за разумную стоимость, при которой вы сможете извлечь прибыль из продажи добытого ресурса. Конечно, назначить заведомо выгодную плату за работу просто на всякий случай, вдруг кто наймётся – это не повредит. Но будьте осторожны, цены на ресурсы падают, и заведомо выгодная вчера оплата сегодня может оказаться выше, чем цена этого ресурса на рынке.
Точно так же и работнику на рынке крайне неудобно: все топовые предложения на самом деле уже выработаны (у рудников ведь есть дневная норма), и реальные предложения начинаются только на третьей-четвёртой странице, а ведь вам надо ещё выбрать апгрейженный рудник на земле с бонусами, чтобы не тратить силы впустую. Механизмов для быстрого отсева предложений нет.
В общем, биржа труда в игре не развита, и полагаться на неё сейчас не стоит.
Демократия
В каждой зоне можно голосованием выбрать мэра. И кандидаты, и голосующие должны достичь 18-го уровня, так что на первых порах демократия вам не светит. Но надо знать, что мэр может устанавливать налог на работу, и в существующих реалиях игры единственный налог, который можно терпеть – это 0%.
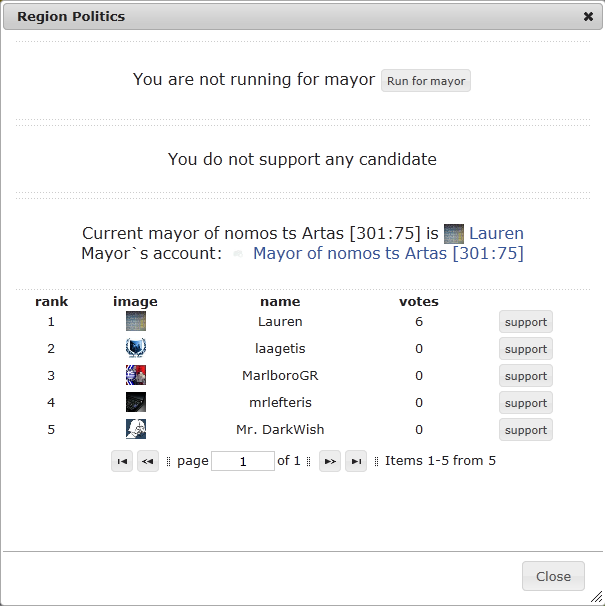
Точно так же, по достижении 21-го уровня можно выдвигаться на пост президента и голосовать за кандидатов. Президент устанавливает налоги на торговлю, и точно так же, единственный налог, который стоит терпеть – это 0%. На нейтрале президента нет и налогов нет.
Учтите, что существуют разные страны и разные коллективы – кое-где пытаются реализовать коммунизм или формы плановой экономики. В таких случаях, разумеется, налоги имеют смысл – и если вы решите присоединиться к такой группе людей, то советы выше не для вас.
Война
На карте мира большинство зон нейтральны, но некоторые помечены названиями стран. Чтобы захватить квадратик, за него нужно воевать – это дело долгое, требует суммарно сотен тысяч энергии, а поскольку влияние ещё и падает со временем, то завоевать квадратик можно только силами десятков людей сразу.
В общем – это дело не для новичков, и если вы с места в карьер не прыгнули в какое-либо плановое общество, где нужно слушать приказ, то воевать вам совершенно ни к чему. Навоюйте 500 очков, как требуется для одного из квестов, и забудьте об этой возможности.
Золото и деньги
Кроме ресурсов, которыми торгуют на рынке, и денег, в игре существует золото. У него особенная роль. Золото нельзя произвести: вы получаете небольшое его количество с каждым уровнем. Поскольку уровни идут всё реже, приток золота вскоре практически прекратится.
Точно то же самое и с деньгами. Общая масса денег на рынке составляется из денег, которые каждый игрок понемногу получает вместе с уровнями.
Золотом, как любым ресурсом, можно торговать. Но оно не нужно ни для каких производств. Золото можно только есть.
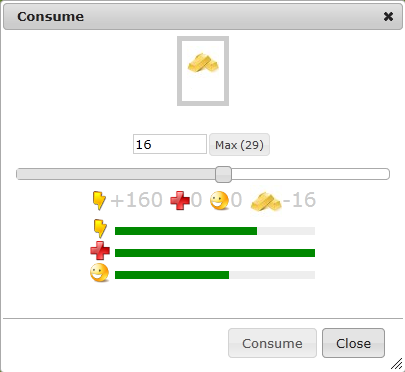
Съев немного обычной еды, вы восстановите свою сытость. Съев немного золота, вы восстановите энергию. Однако обычную еду можно произвести на фабрике, а золото нельзя произвести нигде. Оно прибавляется только с получениями уровней, меняет хозяев на рынке и исчезает, когда кто-то решает обменять его на мгновенный прирост энергии.
Таким образом:
1. Общая масса денег на рынке в целом остаётся неизменной, чуть увеличиваясь с появлением новых игроков.
2. Общая масса золота на рынке в целом уменьшается.
Возможно, это не сразу очевидно, но отсюда следует простая стратегия торговли и потребления золота: золото нельзя есть никогда.
Потратив золото, вы получите энергию, которую сможете употребить на добычу ресурса, который – продать. Но ни один ресурс не стоит таких денег, за какие вы можете просто продать кусок золота.
Более того, количество золота уменьшается, и со временем оно будет только дорожать. Невыгодно продавать золото. Теоретически, золото выгодно покупать, однако сейчас цена золота на рынке завышена, и покупать его тоже смысла нет. Поэтому единственное, что можно делать с золотом – это копить его.
Золото – вложение в будущее, когда в игру придёт достаточно игроков, чтобы рынок золота сначала выровнялся, а потом продолжил обоснованный рост. Таково моё мнение.
Существуют две другие точки зрения на этот вопрос. Одна: золото необходимо тратить, чтобы быстрее восстановить энергию, потратить её, получить опыт, а с ним – уровни, и оказавшись впереди прочих игроков, пользоваться этим преимуществом для извлечения прибыли. Чтобы задействовать эту стратегию, нужно иметь хорошее представление о том, как именно вы собираетесь обналичить своё преимущество в уровне.
Другая: золото необходимо продавать прямо сейчас, получить в своё распоряжение существенно больше денег, и, опять же, раскрутиться за их счёт.
Как зарабатывать
Подведу итог, ещё раз дав простую инструкцию: как зарабатывать деньги, если никаких других идей нет.
Постройте несколько рудников, так, чтобы их дневные нормы выработки перекрывали вашу доступную энергию, работайте на них и продавайте ресурсы по достаточно низкой цене. Если рынок перенасыщен – начинайте добывать другой ресурс.
Чтобы узнать, какие ресурсы требуются, изучите доступные рудники и фабрики и их таблицы апгрейдов. Самый часто требующийся ресурс – дерево, но рынок дерева уже давно перенасыщен. За ним идут кирпич (производится из глины) и железные кубы (из дерева и руды). Потенциал рынка кирпича огромен, хотя сейчас кирпич ещё покупают мало. Рынок железа будет развиваться следующим после насыщения рынка кирпича.
Надеюсь, эти простые соображения послужат отправной точкой для более сложных стратегий трудо- и капиталовложений, которые можно придумывать, немного разобравшись в игре.